|
Will you be Ready? Secure the experienced resources before the rush Get more insight on available options and values |
||
|
|
||
|
Oracle Warehouse Builder (OWB) to Oracle Data Integrator (ODI) |
||
|
The First OWB 2 ODI Converter
References: p.4 "Future database releases beyond Oracle Database 12c Release 1 will not be certified with OWB 11.2.3"
Database & Technology |
Time is flying by... 2014 is now well engaged. If your company is using Oracle Warehouse Builder, time comes you will have to make decisions. Right?! At Oracle, the 12c lifecycle is now engaged!
A migration would have to be contemplated and many factors will have to be taken into account. One of them is the access to experienced resources (see below) when needed. And bad chance could be that everybody wants to move at the same time. Database and Technology (D&T) is an Oracle Gold Partner. Years ago, D&T started developing a migration solution of their own ending up today with the ability to migrate from several OWB release levels to different ODI release levels since with the years, several versions of the OWB2ODIConverter were developed to keep pace with the Oracle releases. This migration/conversion process was implemented several times enabling D&T consultants to gain experience on the subjects. |
|
|
|
||
Tuesday, 28 January 2014
Slowly Converging to ODI ?
Thursday, 7 November 2013
ODI11g - A silent evolution in Version Management? (3/3) - Using "Smart Exp-Imp"
|
|||||
|
|||||
|
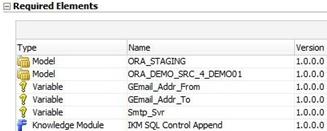
The "principal element" usually a project is pulled into the Smart Export window and the 'Objects to be exported' area and then the procedure collects all the required elements using the known dependencies. As you may see in Fig.02., shared Models, shared Global Objects are collected together with ... the 'Topology specifications stored as you known in the Master Repository. The Logical architecture as well as the Physical Architecture info is picked up (ie: added properties to Data Servers, the connection information to the Development data sources and target, ...) The last may be useful when for instance the url specifications have changed and you would need to test your fix or correction in the same configuration as in Production. Remember, for the "Solutions" one will use the current connection information which might no longer be the same as in Production.
The end result is a complete set that may then be reloaded in a stand-alone, empty Master & Work set of repositories. |
Fig.02. the assembled set of objects and specifications |
||||
|
|||||
|
Personally, I found this process really "smart" and this feature is still currently my favorite option to keep a version of my project code because of its performance versus the "Solutions" option, the available logging/trace during the export step, the autonomy and flexibility it offers afterwards. |
|||||
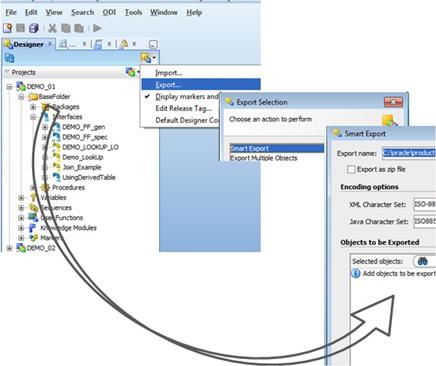
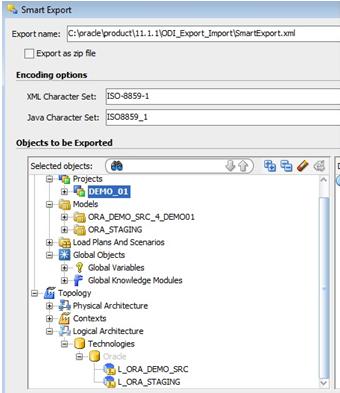
 Fig.03.Smart Import into an empty set of Repos.
Fig.03.Smart Import into an empty set of Repos.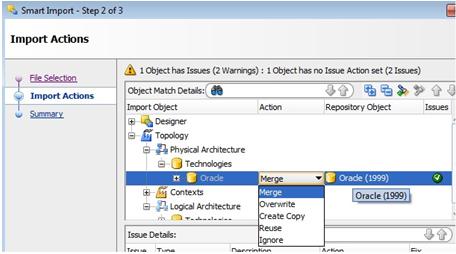
ODI11g - A silent evolution in Version Management? (2/3) - Using "Solutions"
|
||||
|
||||
|
In ODI 11g ... the "Solution" feature further leveraged the ODI versioning feature that enabled a developer keeping copies of specific objects like "procedure", "variable" as a "version" object (kept in a table of the Master repository) independently of any other related object in the Work Repository. |
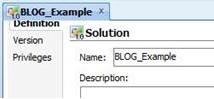
Fig.03. Solution (creating a new container) |
|||
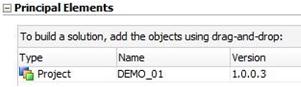
| The Solution container is eventually built as a set of version objects (re-used when they already exist and are current, created when missing in the Master repository table) for all objects (in case of a Project : Interfaces, Procedures, ...) belonging to the main object (Principal Element) dragged and dropped in the "Solution" container and to the related objects of the Principal Element (shared Models, Variables, ...) |
Fig.04 Solution container named Blog_Example |
|||
|
||||
|
Once, the "Solution" has been assembled, it may be shared between all the Work Repositories bound to the (same) Master Repository wherein the version objects have been collected.
In Fig.07, we see a brand new created work repository, still empty. Though, we see the "solution" in the Designer Navigator. The "Solutions" objects are in fact an exception in this GUI sub-part (their specifications are stored in the Master Repository) since specifications of all other objects visible in the Designer Navigator are stored in a Work Repository. .
A usual situation will then be to reverse the 'archived' source of a project into an empty Work Repository in order to bring a 'hot fix' to the code. The developer import the source code from the Master in this empty Work Repository for the purpose.
It is also possible to export a solution into an xml file. In the next post, we will see how it goes with Smart Export-Import ... I must admit now my favorite! |
Fig.07 a 'target' empty Work repository ready for HotFixing |
|||
|
|
||||
|
||||
Sunday, 17 February 2013
ODI11g - A silent evolution in Version Management? (1/3)
| Oracle Data Integrator 11g - A silent evolution in Version Management? (1/3) | |||
|
Version Management with Sunopsis and later ODI has not always been a straigthforward exercise especially when one wanted to externalize a project version to keep this source code together with other pieces of source codes belonging to the same release wave in a third party application dedicated to serve this purpose (ie: StarTeam, ...)
Usually ETL solutions implement a "Project based approach" to support the development around a functional subject. Hence, developer 1 will create his/her project, reverse engineer the data container definitions (files, tables, messages) he/she would have to work with and then he/she would start developing the integration components. All these data container objects will belong to a "project". Developers 2, 3 would do the same and might actually at some point in time have to interact with the same objects (let us take the usual case of a table). Since they would all reverse this object into their own "project" the table's metadata would exist 3 times in their development platform, one time in each project, hence 3 times if we have 3 project/developers working. This configuration will high probably lead to a situation at one point in time where all these objects (the source object in the database, the 3 metadata representations in the ETL solution) will no longer be synchronized. Further, from a 'change impact' perspective, these many representations of a single object (our table) might lead to difficulties in evaluating the impact of a change to this object (finding all the project components touching or interacting with it). There are 'to do's' to manage this.
The ELT-(L) ODI development platform exposes a very specific model or approach. It leverages the nice concept of naturally enabling sharing the representation of source or target objects. The 'data container' metadata would exist only once in the ETL solution and would be exposed to each developer for him/her to interact with. It is then possible to quickly see what are the impacts of a change to this object since all interacting objects (referring to) are exposed as linked to it.
The downsize of this approach would be that the version level of the metadata of this source or target object might no longer be 'in sync.' with the code level in the different projects interacting with it. As a matter of example:
Till Sunopsis v4, the way to address this was to export the complete Work Repository at project code freeze. Sunopsis v4 and ODI till version 10g (and early 11g) offered the concept of "solution" to address this aspect of concurrent development. But it had a downsize, it was a good (internal) answer as long as the implemented ETL solution architecture was revolving around a single Master repository to support the different phases of the development cycle (Development, Test, Quality Control, Production). Since the "Solution" approach relies on objects shared between development repositories attached to the same Master.
The request for separated Master Repositories has raised with time and one had to wait until very recently to have working answers to enable exchanging (or exporting) a complete project source code set (mapping, source-target metadata) In the next parts (2/3, 3/3) of this subject, I shall expose -using the 11.1.1.6.3 version of ODI- how one may from now on address this request. |
|||
Monday, 7 January 2013
ODI11g - Mixing the Security "models" for Authorisations Assignment
|
With Oracle Data Integrator 11g, Oracle extended the Authentication capabilities to be applied to the ODI users. In this post, we will focus on the Authorisation aspects that Oracle Data Integrator inherited from the Sunopsis era. In this inherited approach, the ODI application is implementation with several Security Profiles enabling 'Generic' or 'Non Generic' authorisation profiles. With a 'Generic' profile, the user will have the ability to apply the provided 'methods' to all 'instances' of the object 'class'. For instance, when the method 'delete' is provided for object type 'datastore', the user being assigned this Generic profile will have the ability to apply this method to all datastores. From an administration perspective, this type of profiles are requiring little effort once the users are created with such profiles assigned to them.
With a 'Non Generic' profile, the user will only have the ability to apply the provided 'methods' to the 'instances' of the object 'class' assigned to him/her by the security administrator. For instance, when the method 'delete' is provided for object type 'datastore', the user being assigned this Non Generic profile will only have the ability to apply this method to datastore 'SRC_ORDERS' that has been added under his/her user definition , Instances node. From an administration perspective, this type of profiles are requiring more effort once the users are created with such profiles assigned to them.
A logic like "provide ability to apply the method(s) to all objects except some specific ones" is not immediately available. |
|||
|
Nevertheless, in order to alleviate the administration burden of going for the implementation of 'Non Generic' profiles, the security could look for mixing the 2 approaches. Let's assume several development teams are using the same Work Repository (type Development) and one would like to have each team only operating the objects within a given project.
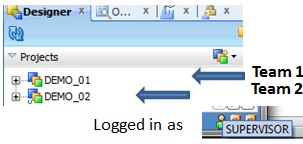
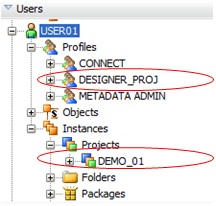
In our example, we have 2 projects (DEMO_01, DEMO_02) and 2 teams materialized by 2 users, where USER01 would belong to Team 01 and USER02 would belong to Team02. |
|
||
|
And for each team, one wants them to have full access to the underlying objects in the Project tree.
From an ODI security perspective, this would be translated as: I want Non-Generic rights for the Project object class and I want Generic rights for all other objects (Interfaces, Packages, Variables, Procedures, ...) under this point in the tree. |
|
||
|
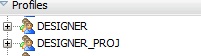
In the Security Navigator, we would then in the Profiles part, pick up the existing 'DESIGNER' profile and duplicate it under the name 'DESIGNER_PROJ'. |
|
||
|
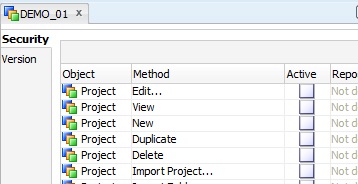
We would then . expand the 'Designer_Proj' profile to . locate the 'Project' node , expand it too and then for each method (assuming we want to kept all methods from the original definition), we would uncheck the [ ] 'Generic Privilege' box on the Definition tab of the methods. |
|
||
|
We then, if not done yet add USER01 and USER02 under the 'Users' module. For each user, we assign - drag and drop - the 'Connect' profile and the newly created 'Designer_Proj' profile to the users.
We then move the 'Security Navigator' (clicking on the icon on the header bar) from the menu (for us on the left side of the ODI Studio) over the Workspace area in order to have both the Designer Navigator (left in the menu) and the Security Navigator (right in the workspace) visible.
We then drag and drop the project instance 'DEMO_01' onto the 'USER01' node in the Security Navigator. We are asked to confirm granting this project to this user, what we do. |
|
||
|
A window is then automatically open in the workspace for you to activate the methods for this object's instance.
. Allow all methods in all repositories . Deny all methods in all repositories . Allow all methods in selected repositories For this example, we 'Allow all methods in all repositories'. |
|
||
|
We may then disconnect and (re)connect as USER01 to have a try at the behaviour. The users (as shown on Fig. ) were also assigned the complementary - and original - profile 'METADATA_ADMIN'. This profile provides a 'Generic' View method on the 'Project' class.
We duplicated the profile 'METADATA_ADMIN' to create a profile 'METADATA_ADMIN_MODELS' without View method on Project and replaced the Metadata profiles on users with the newly created one.
The complete users' profile settings would not be completed at this stage. Nevertheless, as a matter of conclusion, this demonstrates that there are plenty of configurations available (not out of the box unfortunately) in order to mitigate Security requirements and administration burden. |
|||
Monday, 31 December 2012
ODI11g - Which Repository architecture to go for?
Maybe the question would appear quite simple for some people to answer and maybe I am paying to much attention to this point.
To put things in perspective, there is no better way than taking several cases (at least 2) which are completely different and far away from one another in such a way that one will then somehow set the limits of the exercise.
In the Sunopsis period, the sales speech, supported by a designer seat driven licensing model, was to position the product as the solution for multiple Data Integration flows to multiple targets. The ODI repository (the Work repo type development) could then be implemented as a single central metadata repository enabling central impact analysis and central metadata management. This was and still is supported by the fact that the Data Models (as ODI objects) can be shared across projects and are not bound to a Project (as ODI object) in a 1:1 but rather in a 1:M relation.
In the Oracle period started more than 5 years ago, the product has become part of the Fusion Middleware offering and is interacting with many other products that also expose similar functionalities. Oracle has indeed been assembling products in its Fusion Middleware offering that were before (for some of them) competitors with overlapping functionalities (ie: transformations in data integration).
Within the OFM approach, the differentiating (or core) functionalities of these products are kept to fill in the puzzle. ODI within the Fusion Middleware offering could ultimately be seen as the ELT-L mass transformation engine. In this context, it could be reduced to a technical enabler for this function. Within an OFM solution implementation, each data integration flow or process management requiring mass data manipulation could call on its own dedicated ODI implementation to serve its goals.
The 2 ODI architectures at the limits would then look at one end as a single centralized metadata repository managed and organized with a centralisation perspective and at the other end as a free, open, where each developer or group of developers would locally manage their own 'project related ODI non centrally managed implementation' (implicitly with own set of repositories or even a single repository when using the R.C.U-tility).
Experience has often demonstrated that the optimal choice for a given case is to be found between the two limit cases.
Further, one could find oneself initially in front a chaotic, un managed implementation wherein several projects could have been started as 'Proof of Concept' to see their lifecycle extends further the PoC period. A federating process could later take place to eventually have them all under control under a centrally managed approach.
In order to evaluate appropriate alternatives, one would have to set a list of decision drivers and evaluate each extreme possibility against these drivers.
For the sake of illustration, one could start with a couple of driving functions such as:
. the ability to evaluate the impact of change in a data model
when a datastore (as ODI object) is reverse-engineered in several Work Repositories for several projects
it is most difficult to trace the impact of a change to this object
. managing the security of the ODI objects (projects, models, ...)
having one Work repository per development Team requires no fine-tuned security setup
. sharing the model metadata (technical and business related)
. sharing the in-house developed or modified Knowledge Modules
when using a single Work repository in-house developed KM's are easily sharable when placed under
the [Others].[Knowledge Modules] in the Designer Navigator.
But different projects might require different KM's frames or patterns, reducing the necessity to share.
. managing upgrades and homogeneity of the ODI application itself.
Here the lifecycle of the different projects the ODI components are incorporated may be different.
. facilitating the metadata exchange with other metadata repositories (ie: OBIEE)
. the IT organisation by itself (centralized or de-centralized (geographically, Operation versus BI, ...))
. the internal policy regarding version control using ODI repository or an external tool
. the developers' quest for autonomy with regard to Data Models-Datastores specifications
when a developer has to wait for someone else to setup some things in the Data Models before he/she
can work further on the project.
Other aspects like aligning the ODI repository architecture to an Dev/Acc/Prod organization will also have to be taken into account as well as sharing the metadata of each repository types (Master, Work) between these environments.
I personally believe that whatever the repository architecture is eventually retained and implemented, investing upfront time and effort in setting up naming conventions, migration or exchange principles for KM's, projects and more will pay back by itself in the long term.
Usually sooner than expected.
Re-organizing developments afterwards to align them to a 'new' architecture definition will require much time and attention.